| Version 2 (modified by sherbold, 14 years ago) (diff) |
|---|
TracNav
- Home
General Information
- Conceptual Details
- Architectural Details
- For Developers
- Examples
- Downloads
- Documentation
- Credits and Licences
- Legal Issues / Impressum
AutoQUEST Core Library
AutoQUEST Plug-ins
Java Foundation Classes
Microsoft Foundation Classes
HTML- and JavaScript-based Web Applications
PHP-based Web Applications
Generic Event Plugin
- GUITAR
AutoQUEST Frontend
Usage-based Testing
Usage-based testing is one of the quality assurance components provided by EventBench. The rational behind usage-based testing is based on the fact that from a user's point of view, not all parts of a software are equally important. Therefore, from a user's point of view, the testing of all parts of software is not equally important, either. In usage-based testing, the testing effort is focused to reflect this difference in importance.
As a measure for the importance of a piece of software, we use the number of times a functionality of a software is used. This is based on observation of the software in form of usage sequences. A usage sequence is an ordered list of events. Based on the known data about a software, i.e., the observed usage sequences, stochastic processes are trained to define probabilistic usage profiles. The usage-based testing technique are based on the usage profiles.
Usage Profile Types
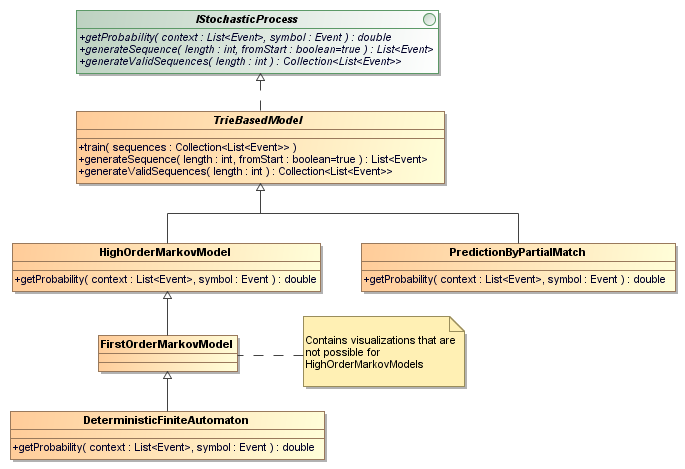
Currently, EventBench supports usage profiles based on for different stochastic proccesses:
- First-order Markov Model (FOMM): In FOMMs the probability of the next event only depends on the last observed events. Using a GUI application as example, this means that the next click of a user only depends on the last click. All previous click do not impact the probability. The advantage of FOMMs is their low complexity. The drawback is that such models are not well suited to even model rather simple preconditions. As an example, consider a form where you need to check two boxes: that you accept a privacy agreement and that you accept the terms and conditions of a product. If only one click is remembered, it is impossible to know if both fields have been checked.
- Higher-order Markov Model (HOMM): In HOMMs the probability of the next event only depends on the k observed events, where k is a positive integer known as the Markov order of the HOMM. Using a GUI application as example, this means that the next click of a user only depends on the last k clicks. All clicks that are at least k+1 clicks ago do not impact the probability. The advantages and drawbacks of the HOMMs are the opposite of the FOMMs. The complexity is exponential in k and can easily get out of hand. On the other hand, if k clicks are remembered, it is possible to model pre-conditions that require up to k events to model.
- Prediction by Partial Match Models (PPMM): TODO
- Random Deterministic Finite Automata (RDFA): TODO
Test Suite Generation Algorithms
TODO
Usage-based Coverage Criteria
TODO
Attachments (1)
- UsageProfiles.png (50.8 KB) - added by sherbold 14 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip