| Version 6 (modified by pharms, 14 years ago) (diff) |
|---|
TracNav
- Home
General Information
- Conceptual Details
- Architectural Details
- For Developers
- Examples
- Downloads
- Documentation
- Credits and Licences
- Legal Issues / Impressum
AutoQUEST Core Library
AutoQUEST Plug-ins
Java Foundation Classes
Microsoft Foundation Classes
HTML- and JavaScript-based Web Applications
PHP-based Web Applications
Generic Event Plugin
- GUITAR
AutoQUEST Frontend
Usage-based Testing
Usage-based testing is one of the quality assurance components provided by EventBench. The rational behind usage-based testing is based on the fact that from a user's point of view, not all parts of a software are equally important. Therefore, from a user's point of view, the testing of all parts of software is not equally important, either. In usage-based testing, the testing effort is focused to reflect this difference in importance.
As a measure for the importance of a piece of software, we use the number of times a functionality of a software is used. This is based on observation of the software in form of usage sequences. A usage sequence is an ordered list of events. Based on the known data about a software, i.e., the observed usage sequences, stochastic processes are trained to define probabilistic usage profiles. The usage-based testing technique are based on the usage profiles. A more detailed presentation of the techniques implemented by EventBench can be found in this dissertation.
Usage Profile Types
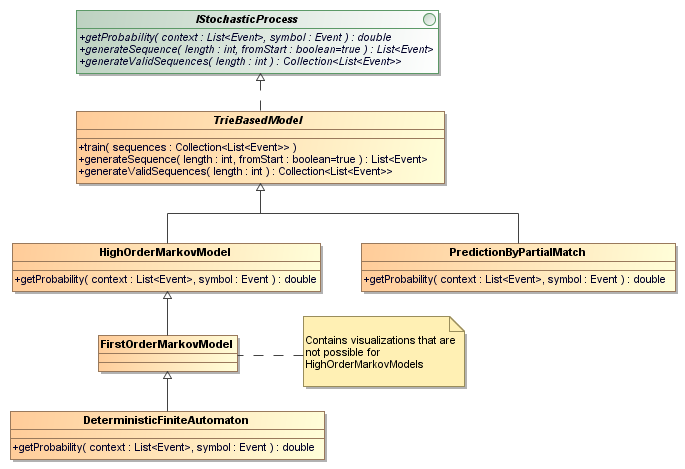
EventBench supports usage profiles based on four different stochastic proccesses:
- First-order Markov Model (FOMM): In FOMMs the probability of the next event only depends on the last observed events. Using a GUI application as example, this means that the next click of a user only depends on the last click. All previous click do not impact the probability. The advantages of FOMMs are their low complexity and high flexibility. With flexibility, we mean that a lot of scenarios have a positive probability in the FOMM, because only the last event impacts the probability. The drawback is that such models are not well suited to even model rather simple preconditions. As an example, consider a form where you need to check two boxes: that you accept a privacy agreement and that you accept the terms and conditions of a product. If only one click is remembered, it is impossible to know if both fields have been checked.
- Higher-order Markov Model (HOMM): In HOMMs the probability of the next event only depends on the k observed events, where k is a positive integer known as the Markov order of the HOMM. Using a GUI application as example, this means that the next click of a user only depends on the last k clicks. All clicks that are at least k+1 clicks ago do not impact the probability. The advantages and drawbacks of the HOMMs are the opposite of the FOMMs. The complexity is exponential in k and can easily get out of hand and the HOMMs are less flexible because they remember k events. On the other hand, if k clicks are remembered, it is possible to model pre-conditions that require up to k events to model.
- Prediction by Partial Match Model (PPMM): PPMMs are a combination of Markov models with different Markov orders. In principle, a k_max order PPMM is a HOMM with Markov order k_max. However, the PPMMs have an opt-out probability escape, with which a lower Markov order is used. This is bounded by a minimal Markov order k_min for which we set the opt-out probability to zero. The PPMMs, therefore, combine the advantages and drawbacks of the FOMMs and HOMMs in terms of modelling of pre-conditions and flexibility.
- Random Deterministic Finite Automata (RDFA): The RDFAs are a subtype of the FOMMs. They structure is the same as a FOMM, the difference lies in the calculation of the probabilities. In an RDFA, all possibly following symbols have the same probability.
The usage profiles are trained from a set of sequences. These sequences are obtained from observing a System Under Test (SUT). From an implementation point of view, all usage profiles implement a common interface IStochasticProcess. Furthermore, a skeletal implementation for usage profiles that can be based on a trie is provided.
Test Suite Generation Algorithms
There are three randomized test suite generation algorithms implemented by EventBench:
- Random Walks: Generates event sequences by randomly walking a usage profile. This means, that each consecutive state is drawn randomly with respect to the distribution described by the usage profile. This is repeated, until either the END state of the usage profile is reached or a desired test case length. By repeatedly drawing event sequences with random walks, the test suite is generated.
- All-possible Approach: Generates a test suite by drawing from all possible test cases of a given length. First, all possible test cases of the given length are generated. Then, the probabilities of each test case according to a usage profile are calculated, which defines a probablity distribution over the possible test cases. Then, a test suite is generated by repeatedly drawing test cases according to this probability distribution.
- Hybrid Approach. A mixture of Random Walks and the All-possible Approach. First, a test case is drawn with the all-possible approach up to a given length. Then the test case is completed up to a desired length with a random walk.
Furthermore, a heuristic to generate usage-based test suite is provided:
- Greedy Heuristic: Generates a test suite by repeatedly added the test case from a set of candidate test cases, that increases the usage-based coverage (see below) the most. This procedure is repeated, until a desired coverage is reached.
Coverage Criteria
Coverage criteria are an important means for the analysis of how well a test suite actually tests a piece of software. The coverage criteria can be defined on different levels of abstraction, examples are the requirements coverage (which percentage of the requirements do we test at least once) on a very high level of abstraction and the statement coverage (which percentage of the source code statement do we execute at least once during testing). With event-driven software, it is common to employ event-based coverage criteria (which percentage of the possible event sequences of a given length do we execute during testing).
What all of these coverage criteria have in common is that each requirement, statement, or event sequence, respectively, is treated and weighted equally. The actual importance for the software is not included. This is a problem, when it comes to evaluating test suites that follow a usage-based approach. Here, we do not care about the percentages that are covered. Rather, we want the highly used parts to be well covered. To this aim, EventBench allows the calculation of usage-based coverage criteria. In the usage-based coverage criteria, not everything is treated equally. Instead, everything is weighted by how probably it is according to a usage profile. Hence, the usage-based coverage criteria calculate the probability mass of a test suites usage instead of the percentage.
The EventBench implementation allows the calculation of the following coverage criteria, both with percentages and without usage-based weighting:
- Possible depth d event sequences
- Observed depth d event sequences (in relation to s set of sequences)
- New depth d event sequences (in relation to a set of sequences)
Attachments (1)
- UsageProfiles.png (50.8 KB) - added by sherbold 14 years ago.
{kind=link}
Download all attachments as: .zip